
Loop Engineering in the Context of Personal Agents
Published on 6/16/2026
One Friday evening, I asked the AI helping me with a project retrospective: "The database migration plan we discussed last month — why did it get dropped?"
The AI said: "I don't have memory of that conversation." Or maybe: "I know the migration didn't move forward, but I don't know why."
The reality is, that discussion's conclusion directly shaped our technical direction for the next three months.
That's when it hit me: what should an AI actually remember across Loops?
Loop Engineering Isn't "Repetition" — It's "Evolution"
In the AI Agent world, a Loop is typically understood as: perception → reasoning → action → feedback → perception again. It's been equipped with goal setting, heartbeat mechanisms, scheduled tasks, connectors, and memory.
But most AI products handle Loops by starting fresh every time. The conclusions from the last conversation don't automatically become the basis for the next round of reasoning. You think you're in a "continuous collaboration," but the AI is actually starting from scratch every single time.
What Loop Engineering really solves: making every Loop build on the last one — not repeat it. Ultimately synthesizing and deducing toward the final goal.
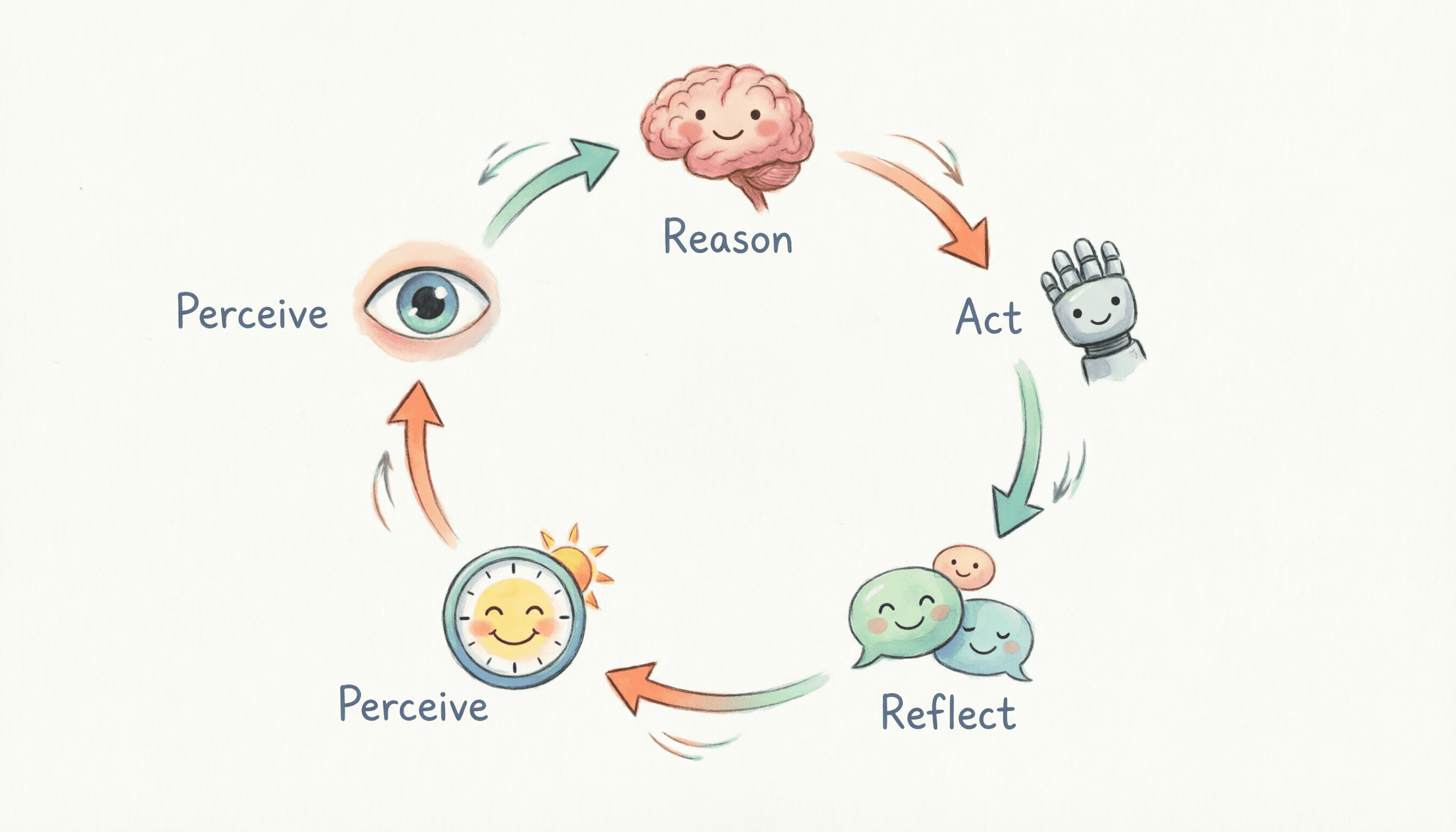
Sounds simple. Hard to actually pull off. The core difficulty is memory.
Memory Brittleness: The Fundamental Flaw in Most AI Memory
I call this problem Memory Brittleness.
Most AI products' memory mechanisms have three root defects:
1. Stored but can't be retrieved
The information exists, but without context linkage, the AI can't retrieve it when needed. You ask about "the plan we discussed last week" and the AI shuffles through chat history, completely lost — it's not that the data wasn't saved, it's that it can't be found.
2. Retrieved but can't be used
Even when relevant information is found, the AI lacks temporal dimension and importance ranking. It doesn't know whether this piece of information is a decision foundation from three months ago or just a casual remark from yesterday. No way to weight it during reasoning.
3. Stored but can't be trusted
Traditional memory is just raw message storage. The AI doesn't know what it has remembered, for how long, or how reliable it is. The reasoning outputs become unpredictable as a result.
Without solving these three problems, a Loop is just repetition, not evolution.
Turning AI Memory from "Hard Drive" into "Brain"
OpenLoomi's answer is the Holistic Context — a structured memory network with both temporal and spatial dimensions. (OpenLoomi is is a Claude Cowork-style open-source alternative for builders who want local-first work memory around their AI agents. It connects your work tools so AI can understand people, projects, decisions, and follow-ups before it acts with human approval.)
Holistic Context
The thing that impressed me most about Coding Agents: their workflow is naturally a closed loop.
An Issue is created → someone designs a solution → code is written → tests are run → PR is merged → Issue is closed → CI/CD → deployed → feedback loop. Every step has state, has a timestamp, has context linkage — ultimately forming a complete engineering trace.
This pattern gave us the insight.
If we design AI memory the same way — not flat storage of information, but like a Coding Agent, giving every piece of memory a timeline, context relationships, and state transitions — then AI memory is no longer a "hard drive," it's a "graph." Every state change becomes a memory node, nodes connect to each other, forming a reasoning traceable context network.
When the AI sees a new Issue you file, it knows when this issue was created, on which branch, what review comments are attached, and how it was ultimately resolved. Not an isolated data point, but a knowledge node with engineering context — with the people and events involved inside.
Inspired by the Coding Agent closed loop — connector data comes in → understanding → structured insight precipitation → next invocation → iteration continues.

Public/private data → Standard raw messages → Summary → Agent updates Insight
→ Structured memory insight → Agent reads/updates Insight → Timeline
→ Global relation graph → Self-evolving memory-precipitated content assetsCoding Agent taught us something: a good closed loop doesn't repeat — it moves one step forward on top of the last cycle. It can continuously deploy, continuously iterate, ultimately completing the goal.
The Context Graph is the closed loop at the Memory level — every insight precipitated from one Loop becomes the reasoning foundation for the next Loop.
Why This Matters Critically in Personal Agent Scenarios
1. Accuracy improvement: from "guess" to "know"
The problem with traditional RAG: retrieval itself is blind. You search for "Project X" and it might return 10 pieces of irrelevant content.
Context Graph lets AI first understand the temporal position and context relationships of information, then decide how to use it. Accuracy improvement doesn't come from a better embedding model — it comes from a fundamental change in memory structure.
2. Cost savings: 60% Token consumption reduction
When AI needs to recall project context, it can:
- Directly query structured Insight, instead of pulling entire conversation history
- Use Timeline to quickly locate relevant memories, instead of scanning all records
- Apply local preferences to override global context, instead of loading complete context every time
3. Every Loop evolves, not repeats
In high-frequency usage scenarios (like a daily-active Coding Agent), the Context Graph's self-evolving mechanism lets AI automatically:
- Keep frequently accessed information "active"
- Archive but not lose low-frequency but important information
- Auto-link new information with old knowledge, forming a more complete graph
The AI in the 10th Loop is genuinely smarter than the AI in the 1st Loop.
Three Typical Use Case Scenarios
Content Automation
AI-driven content creation needs to understand brand voice, user preferences, and historical winners. Context Graph lets AI remember which headline types drove high click-through rates, users' reading habits, and competitive content differentiation strategies. Not re-"learning" every time, but building on yesterday's shoulders.
Coding Agent
What developers struggle with most isn't "AI can't write code" — it's "AI doesn't understand my codebase." Context Graph lets AI remember project architecture decisions, pitfalls and solutions, code style and naming conventions. This is a Coding Agent that truly knows you.
Web3 and DAO
Decentralized community decisions are scattered and context is fragmented. Context Graph helps AI track complete discussion chains of governance proposals, remember community members' expertise and contribution history, and integrate cross-platform (Discord, Telegram, Forum) fragmented information.
The Future of Memory: Structured Insight Beats Raw Storage
When we judge whether an AI memory system is good, we don't look at how much data it stored — we look at three core metrics:
- Can it quickly find relevant memories? — Context linkage capability
- Are the memories found trustworthy? — Knowledge graph accuracy
- Can memory guide current decisions? — Insight actionability
Context Graph doesn't store all data — it turns data into reason-able knowledge.
In the Loop Engineering context, real progress isn't "AI completed another Loop" — it's "AI invoked the last Loop's memory in this Loop and made a better decision."
Your AI memory should be a living knowledge graph, not a hard drive that forgets.
| Resource | Link |
|---|---|
| OpenLoomi GitHub | openloomi-memory |
| Skills Documentation | openloomi-connectors |
Check Out the Code
Star the repo, read the source, open issues, or fork it — everything lives there.