
Agent Memory Evaluation Pain Points: OpenLoomi's Memory Growth Journey
Published on 6/15/2026
Memory is the most important — and most difficult to measure — capability for AI agents. Our struggles and breakthroughs along the way.
The day we first tried to evaluate our memory system rigorously, we realized we had a problem.
Not with the memory itself — but with how to prove it worked. How do you measure whether an AI actually remembers the context of your work over weeks and months? How do you compare two memory systems when "remembering" means different things in each one?
These questions sent us down a two-year rabbit hole. This is what we learned.
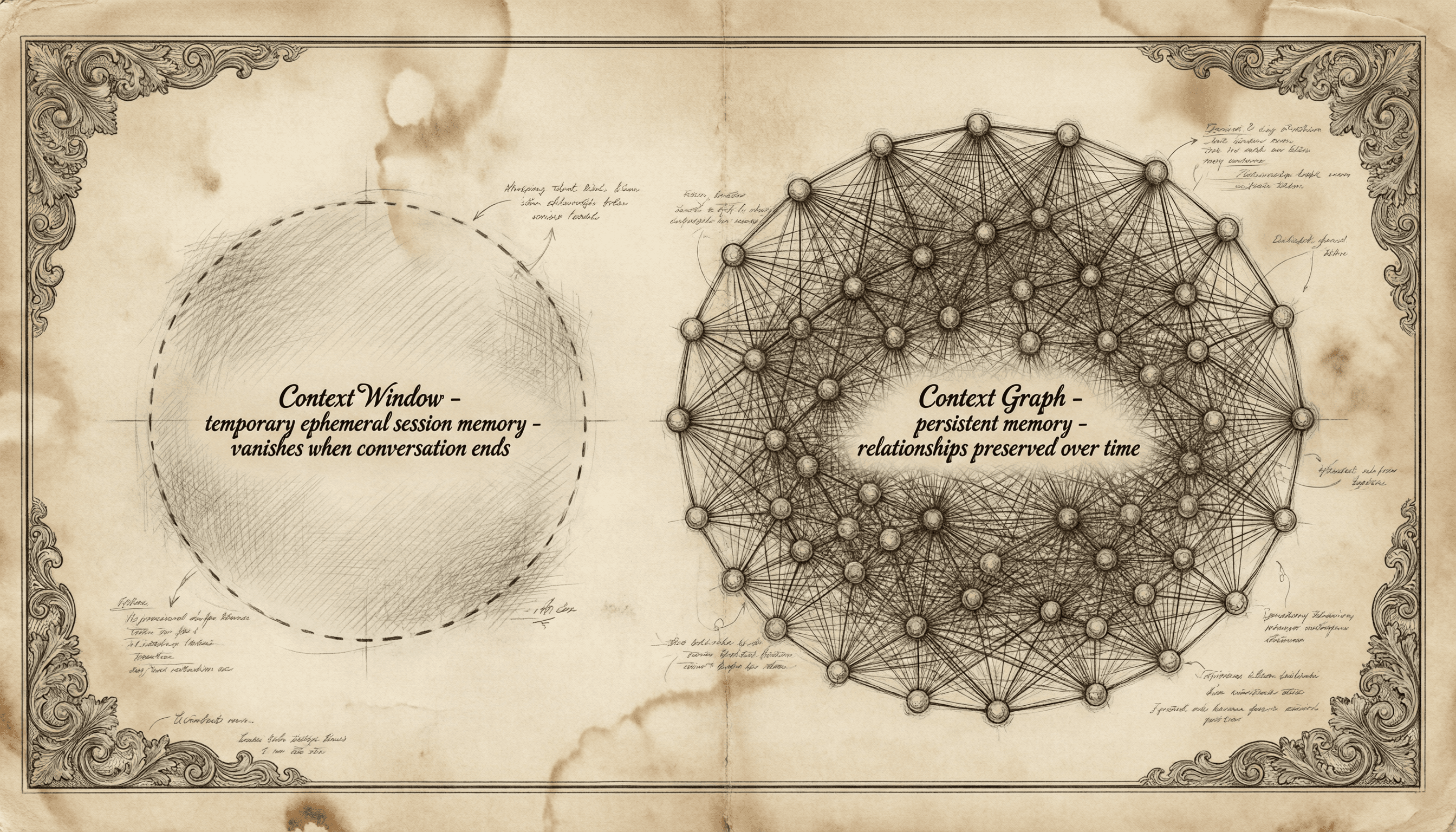
The Context Window Problem
Every AI tool today has a context window — a temporary workspace where information lives for the duration of a conversation. But what happens when the conversation ends? What about last week? Last month?
Context that doesn't persist isn't memory. It's just a longer prompt.
OpenLoomi was built on the premise that AI should have a persistent, evolving understanding of your work — not just the current session, but everything that came before. Your projects, your decisions, your communication patterns, your priorities.
We call this the context graph. Building it was only half the battle. The other half was figuring out whether it actually worked.
Four Things We Didn't Expect
Before we could evaluate anything, we had to understand what we were actually measuring. Turns out, memory evaluation isn't one problem — it's four distinct challenges that compound each other.
Memory Brittleness
Traditional RAG systems retrieve facts. OpenLoomi tries to preserve contextual relationships — who said what, when, why it mattered, how it connects to what came before.
The problem: factual retrieval is easy to measure. Contextual coherence is not.
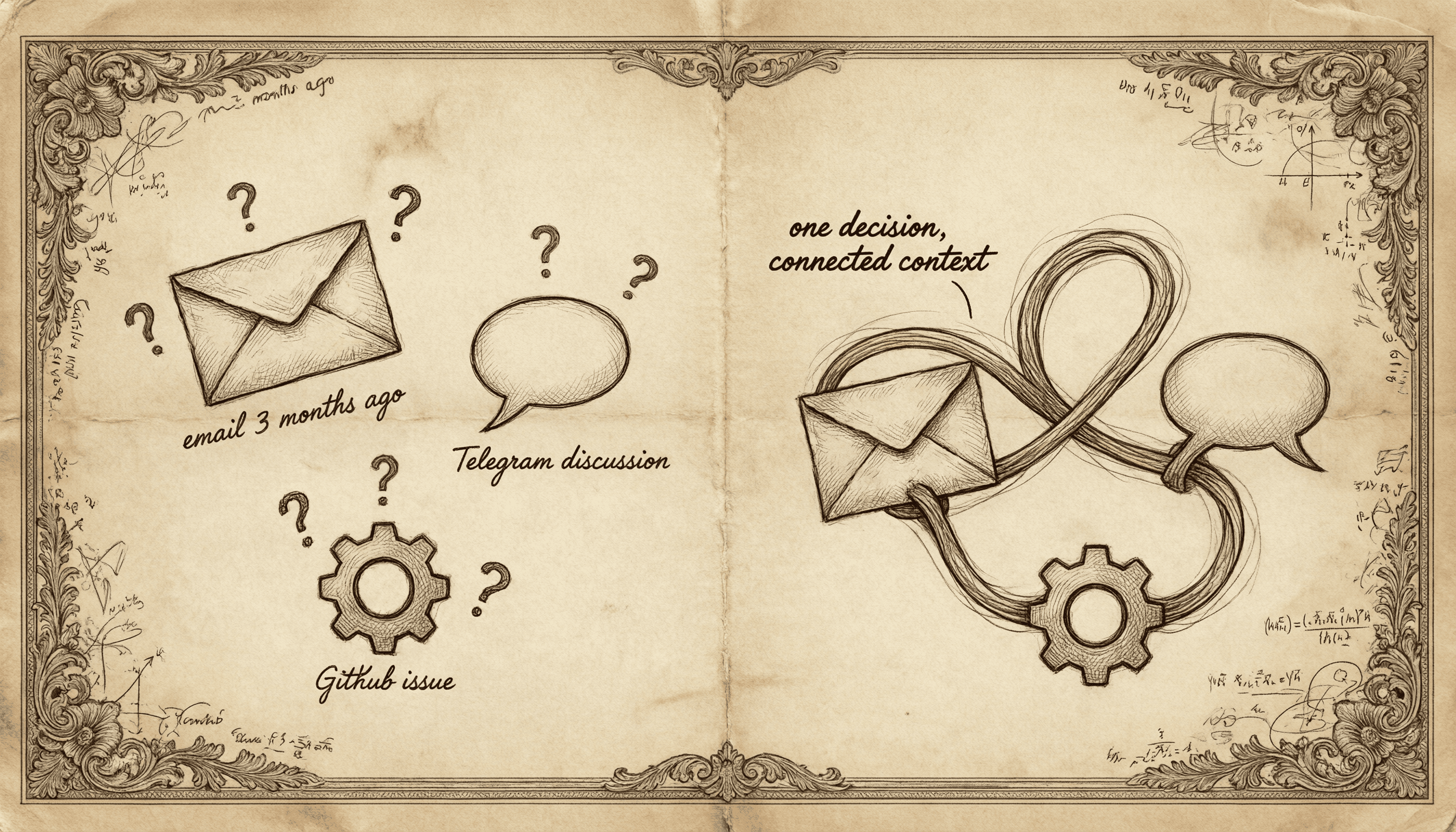
Here's what we mean. Three months ago you discussed a technical solution with a client over email, debated the budget in a Telegram group, and logged review conclusions in a GitHub Issue. In real life, these are three sides of the same decision. But in a fragmented storage system, they're three completely independent records. Vector retrieval can surface all three, but the system doesn't know: these three things are about the same decision, which was later revised twice, and the current version is X.
So the AI gives you raw materials, not context. You think it's helping you remember — but it's actually handing you archaeology.
Fragmented information in, fragmented information out.
A system can return technically correct documents while missing the whole point of the query. We needed metrics that captured whether the AI understood the meaning of what it remembered, not just keyword overlap.
Temporal Reasoning
"Remember the project we discussed three weeks ago" — this sounds simple but requires understanding time windows, recognizing which memories are still relevant, and knowing how to update or override past context.
Time is not just a filter. It's a reasoning dimension.
Most evaluation benchmarks treat time as metadata. We needed to treat it as a first-class reasoning challenge.
Forget Nothing ≠ Remember What Matters
Here's the paradox: storing everything is not the same as remembering what matters.
Every AI system has finite context. Loading 10,000 past messages doesn't help if the relevant signal is buried. The real skill is prioritization — surfacing the 1% that actually resolves the current query.
This is where the "Forgetting Engine" became crucial. We don't just store; we actively age out noise and elevate signal.
The Evaluation Dilemma
Here's the uncomfortable truth: most memory benchmarks measure the wrong things.
Generic benchmarks gave us numbers. We needed something that actually reflected real-world performance.
What We Built
Holistic Context
The context graph is not a vector store with better branding. It's a structured representation of memory relationships that captures temporal edges (what happened when), semantic clusters (related concepts grouped together), and access patterns (what gets retrieved together).
When you ask "what was the feedback on the API redesign?", the context graph doesn't just match keywords. It traces the conversation chain that led to that decision, understands the project structure, and recognizes which stakeholders were involved.
What does this look like in practice? A founder fundraising might ask "what was our judgment on this market back then?" — they need to retrieve the market understanding they had at that time, not today's retrospective view. A project manager asks "how was this requirement decided three months ago?" — they need the original decision chain, not a timeline of all versions. A salesperson asks "where did we left off with this customer?" — they need the progress snapshot from last time, not all communications to date.
The difference between a history list and a historical state snapshot is the difference between archaeology and time travel.
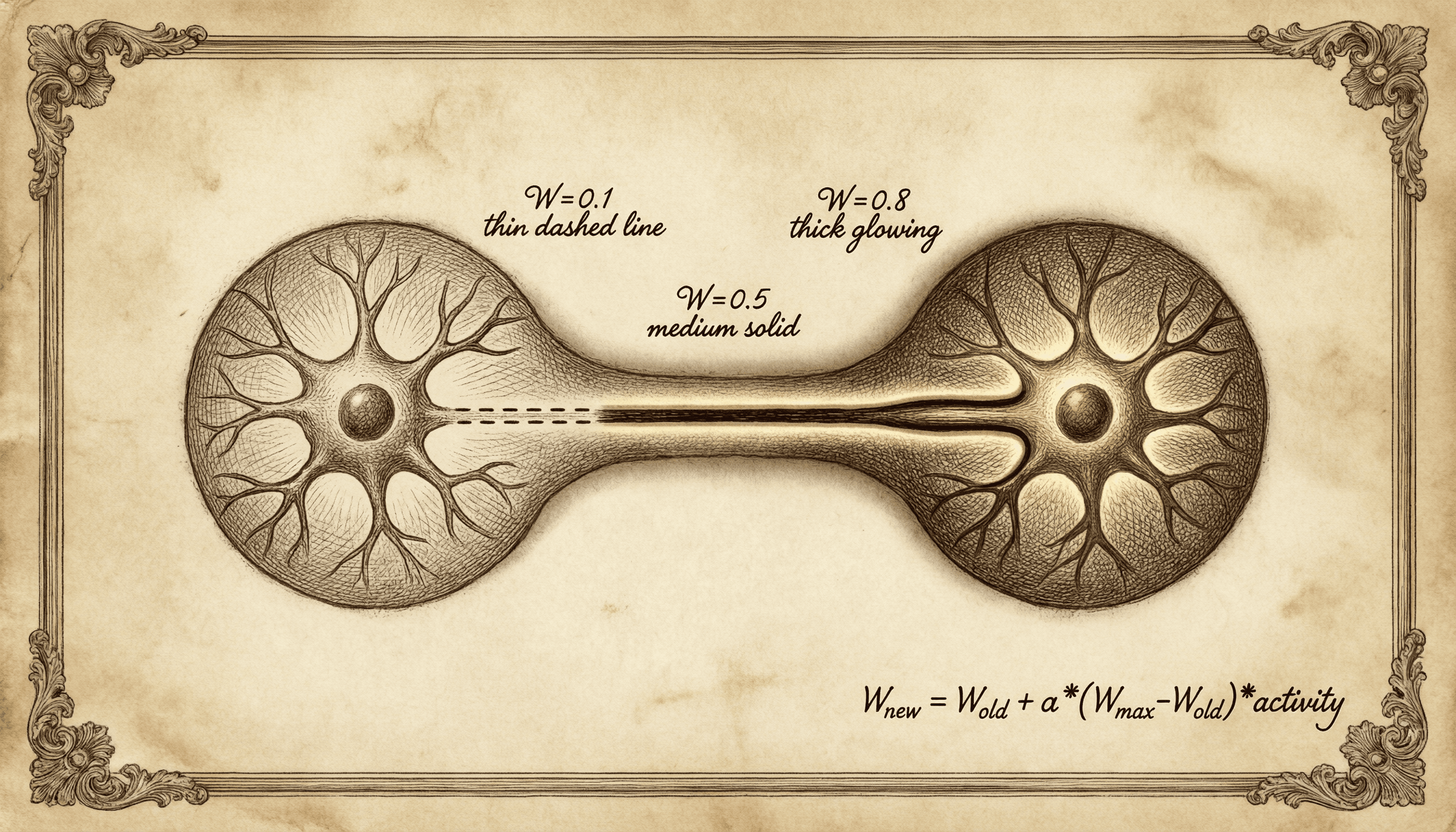
Hebbian Memory Connections
Inspired by Hebbian theory — "neurons that fire together wire together" — we built associative memory links that strengthen based on co-occurrence.
When you access Insight A, the system checks recent accesses with similar keywords or semantics. If a connection already exists with Insight B, it applies potentiation (strength *= 1.2, stability *= 1.1). Otherwise, it creates a new connection with strength = 0.1.
Memory should infer relevance, not wait to be asked.
For example, during a quarterly review when you ask "why did we choose Plan A for this project?", the system doesn't just return Plan A's content. It automatically surfaces related context: "you also looked at Plan B and Plan C", "you discussed budget concerns", "Li Si made the final call" — associations the system learned from your actual work patterns, not semantic similarity.
The connection strength formula: Wnew = Wold + alpha * (Wmax - Wold) * activity, with decay following Wdecay = w * e^(-yt).
Time-Travel API
We built the ability to query memory as of a specific point in time:
node $SKILL_DIR/scripts/openloomi-memory.cjs get-insights-as-of 2024-01-01
node $SKILL_DIR/scripts/openloomi-memory.cjs get-current-insights
node $SKILL_DIR/scripts/openloomi-memory.cjs get-insights-overlapping 2024-01-01 2024-03-01This breaks the static memory time barrier, enabling "time travel" queries that see what insights were relevant at a specific point in time. Useful for both honest evaluation ("did our memory actually have this fact at that time?") and debugging how context evolved.

Forgetting Engine
The forgetting engine is not about deletion. It's about progressive summarization and archival.
Phase 1 handles Short → Mid transitions: scan L1 memory records, score them, and if below 0.65, promote to the next tier with a generated L1 Summary. Phase 2 handles Mid → Long: scan L2 records, score below 0.45 triggers promotion with L2/L3 Summary generation.
The system actively manages its own relevance, rather than accumulating everything indefinitely.
How We Evaluated
We assessed four dimensions: Accuracy (how well answers match facts, using F1-Score, BLEU), Recall Rate (how well the system retrieves and associates relevant information), Temporal Reasoning (ability to handle time-sensitive queries), and Knowledge Update (dynamic adaptation when knowledge evolves).
LoCoMo
LoCoMo from Stony Brook University contains real conversation records with observations, summaries, and QA pairs. Question categories include single_hop (single memory retrieval), temporal (date/time reasoning), multi_hop (cross-session multi-step reasoning), and open_domain (open-domain Q&A).
LongMemEval-S
500 QA pairs from real multi-turn conversations, evaluating 6 question types across 10+ sessions. Single-session retrieval, multi-session reasoning, temporal reasoning, and knowledge update all show strong performance.
Context Learning
Context Learning evaluates complex multi-modal memory reasoning tasks. We're still working through this benchmark — results aren't where we want them yet, and we're iterating on the evaluation methodology itself.
Why Existing Benchmarks Fall Short
Honestly, we spent months trying to use generic benchmarks before realizing they weren't capturing what we actually cared about.
Data Distribution Distortion — Real scenario data is sparse, multi-modal data is scattered with high noise, and overall too static. The Ground Truth itself has labeling errors.
Missing Core Data — Important real-scenario data like relationship networks is ignored. There's no continuous tracking and analysis of event development, making it hard to evaluate memory logic and coherence.
Evaluation Effect Distortion — Due to rapid iteration of model reasoning capabilities, past benchmark achievement thresholds and validation effects have dropped significantly. Tests pass but real business performance is poor.
New Benchmark Urgently Needed — Like SWE-Bench and Programming Bench in software engineering, there's a lack of standard evaluation for real business scenarios.
Five Things We Learned
After two years of building, evaluating, and iterating, here are five things we wish we'd known from the start.
Memory isn't the longer the better. Long-term memory without proper organization and retrieval just creates noise. Quality of memory context matters more than quantity.
Forgetting algorithm is harder than storage algorithm. Figuring out what to discard is more challenging than deciding what to keep. A good forgetting algorithm requires understanding relevance, recency, and usage patterns.
Scoring weights need self-evolution. Static scoring doesn't work. Weights for recency, importance, and access frequency need to adapt based on actual usage patterns and feedback.
Evaluation system is the foundation for iterative improvement. Without proper benchmarks, you can't measure if you're getting better or worse. Building an evaluation framework isn't optional — it's the prerequisite for systematic improvement.
Context accuracy needs to consider time-space dimensions. A fact stated three months ago has a different weight than one from yesterday. Time and spatial context are essential for determining what "accurate" memory really means.
What's Next: Spark Benchmark
We're building a new evaluation framework called Spark.
Spark targets workplace full-context graphs, comprehensively evaluating people, projects, decisions, workflows, and their complete evolution. The core differences: focus on spatio-temporal and full-domain relationship graphs, and composite evaluation that assesses overall correctness of complex questions, not just single-point accuracy.
Example scenarios: Relationship Graph Construction tests whether the system can precisely identify team members' role positioning, cooperation relationships, and cross-department collaboration links. Project Risk & Problem Alerting tests whether it can mine potential risks from project execution context and predict key node delays. Historical Experience Precipitation & Reuse tests whether it can extract project success paths and failure lessons into reusable organizational knowledge.
Beyond Spark, we're also working toward memory models that fundamentally solve information forgetting, context disconnection, and "starting from scratch every time."
Join Us
Memory is the hardest unsolved problem in AI. We don't have all the answers — but we're building in the open and learning in public.
OpenLoomi is open-source. The memory system is yours.
Check Out the Code
Pull requests, issues, and discussions welcome.